Key Elements to Make Fluid Ownership Work
Focus for Longer
In contrast to the previous organizational design pattern that leads to considerable context switching between projects and tasks to keep people and teams busy within their responsibilities, this organizational design pattern allows—well, requires—a different approach, allowing people to focus on a certain outcome for a longer time period.
Even though in the world of software product development today’s expertise will be less useful in the future, we must still take it into account! When there is a high level of context switching due to lack of focus, this leads to
-
Jumping from one defect to another, and another, and another…
-
Starting something else while waiting for feedback on another aspect.
-
The continuous switching of priorities by (project) managers due to a lack of vision and strategy.
-
Being allocated 20% on one project, 10% on another, etc.
Each time someone has to switch from one thing to another, they must unload and load the knowledge needed to execute the task at hand. This increases cognitive load significantly for all involved, and on top of that, it causes significant stress.
Organizations that have a good vision and strategy, sequencing bigger needs and problems that have to be worked upon (= outcomes), will generally provide an opportunity for teams to focus on a certain need or problem for a longer time—from a couple of weeks to a couple of months. This kind of high focus will increase expertise on what’s being done at that time and thus lower the cognitive load for all involved. At the same time, this is a great way to enable short feedback loops, again lowering the overall cognitive load.
Additionally, organizations without a good vision and strategy will, consequently, need to jump from one priority to another, all with their own (imaginary) deadlines. This will cause more stress for teams, resulting in a high chance they will ignore technical excellence and start to deliver low-quality solutions built on ugly architectures. We must consider that agility is not about jumping from one priority to another; rather, it is having the ability to learn and adjust course while discovering solutions to needs and problems. A narrative of an organization that made similar realizations can be found here, in Chapter 3.2.1 on "cognitive load": https://less.works/case-studies/ysoft#32-narrative
We focused on switching context in terms of the things we have to do, as well as how switching the "how" of implementing a feature makes it difficult to build permanent knowledge—for example, switching from one service to another service. To make this easier to handle, different options are listed in the other ways to reduce cognitive load e.g., standardization and guidelines, clean code and architecture, small changes, etc.
Evolutionary Design
Evolutionary design is a concept in software development that refers to the process of developing software systems that continuously evolve and improve over time rather than being fully specified before any code is written. This approach allows software product development organizations to adapt software design based on changes in customer requirements, market conditions, or technological advancements.
In the functional domain, evolutionary design emphasizes incremental development, where features are progressively added and refined based on ongoing feedback from users. This aligns with Agile practices, where the primary goal is to deliver working software that meets users' needs at every stage of development. By focusing on user feedback and real-world usage, teams can identify the most valuable features and prioritize those in development cycles. This ensures that the software remains relevant and highly tailored to user requirements over time, allowing the application's functionality to evolve in direct response to user needs and behaviors. See the subsequent chapters for more details on this phenomenon.
In the technical or architectural domain, evolutionary design involves iteratively refining the system's architecture to support its growing and changing functionality. As new features are added and existing ones are modified, the underlying architecture may need to adapt to ensure the system remains robust, scalable, and maintainable. This approach requires a strong foundation in coding practices that promote modularity and extensibility, such as tidying code, refactoring, and the use of design patterns that accommodate change. Technical debt is actively managed to prevent it from undermining the architecture's evolving ability. Teams focus on building systems that can easily be modified without extensive rework, ensuring that the architecture can evolve parallel to the software's functional aspects, thereby supporting continuous improvement and adaptation over the software's lifecycle.
In short, the technical architecture will evolve over time, in line with customer needs and the focus at that time. It is our experience that peer accountability, group pressure, intrinsic motivation, direct coordination, and alignment (mentioned earlier) will provide sound grounds on which to keep the overall technical architecture effective and clean, without the need for a central policing unit.
It is unlikely that a team familiar with certain architectural patterns in one part of a solution will be able to execute something else completely somewhere else in a solution—we like to take the path of least resistance and will apply what we know already.
Evolutionary design in both domains together allows for the creation of software that is both functionally rich and technically sound, facilitating ongoing adaptation to new challenges and opportunities as they arise.
Proximity to Those Consuming the Value Created
A big cause of high cognitive load is trying to figure out the intent of provided requirements. Since this is so difficult and time-consuming, most people give up and simply implement the most likely interpretation, without a full understanding of the context, intent, or objective of the requirement, even if the written requirement document is suspected of being wrong. The penalty for this behavior is a constant change of requirements and a stream of bugs due to incorrect implementation caused by not understanding intent.
In reality, most so-called requirements changes don’t occur because requirements changed; rather, they were not understood or validated in the first place. These fake requirements changes exacerbate the problem of cognitive load even further. A team will be constantly surprised (more annoyed and frustrated) by these changes, which are often discovered late and needed to be fixed yesterday.
Most of the cases outlined above don’t occur because of people’s poor intent; it is because of the numbers of handovers between those consuming the value and the ones generating the value, by means of written documentation. This is the least-effective way to mutually understand ideas.
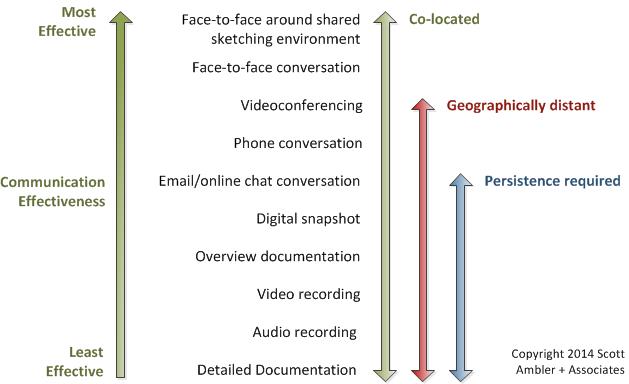
Source: https://agilemodeling.com/essays/agileDocumentation.htm
We are all aware of the concepts of Chinese whispers or broken telephone syndrome from childhood. We had to read from a piece of paper, whisper it into another person’s ear, and they whisper it to another, and this occurs around 5 times, from one person to the next. Then, the last person must write down what was understood. What was written at the start is never what is written at the end! See: https://youtu.be/evHpxNeX-9c
The assumption many take for granted is that teams should not be involved in product discovery and instead should focus on delivery. This usually increases cognitive load since teams receive information late from those who prepare information; write stories and product requirements documents (PRDs); construct designs, etc. Teams must then make assumptions about actual customer needs or problems and what they mean, as they were not involved in these discussions. Whenever priorities or anything in those prepared documents change, the teams discover this late—typically just before or during delivery, leading to more context switching and lack of focus, increasing the overall cognitive load and stress. See: https://youtu.be/YeNgL24j72c
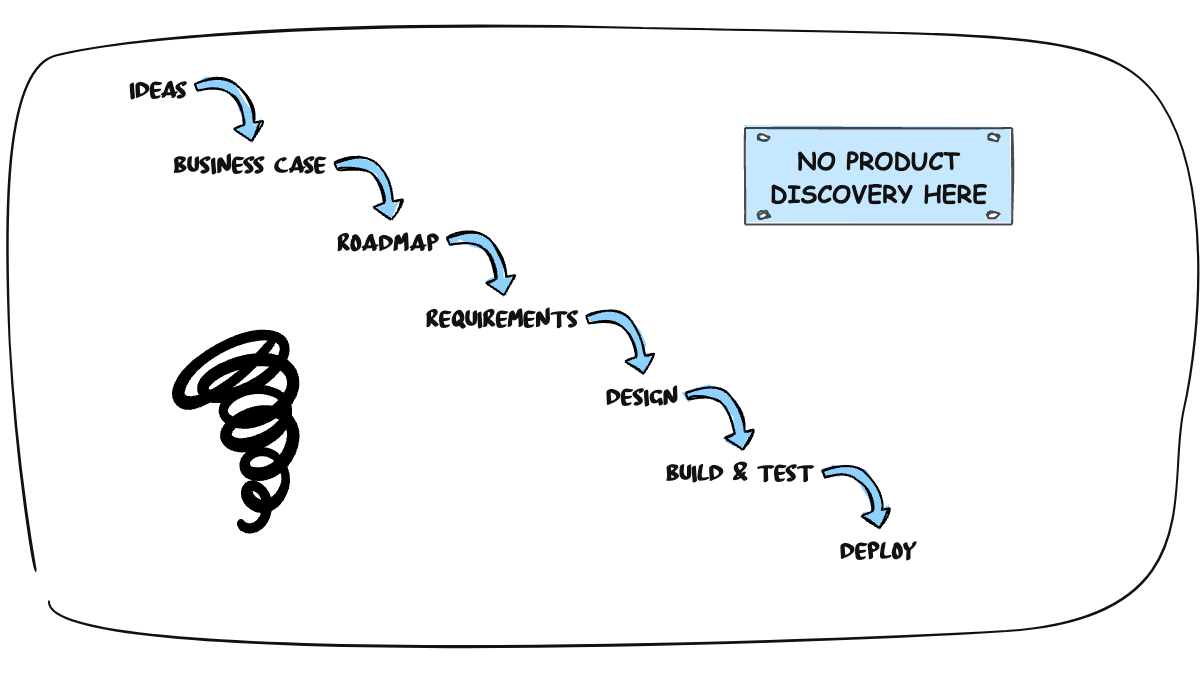
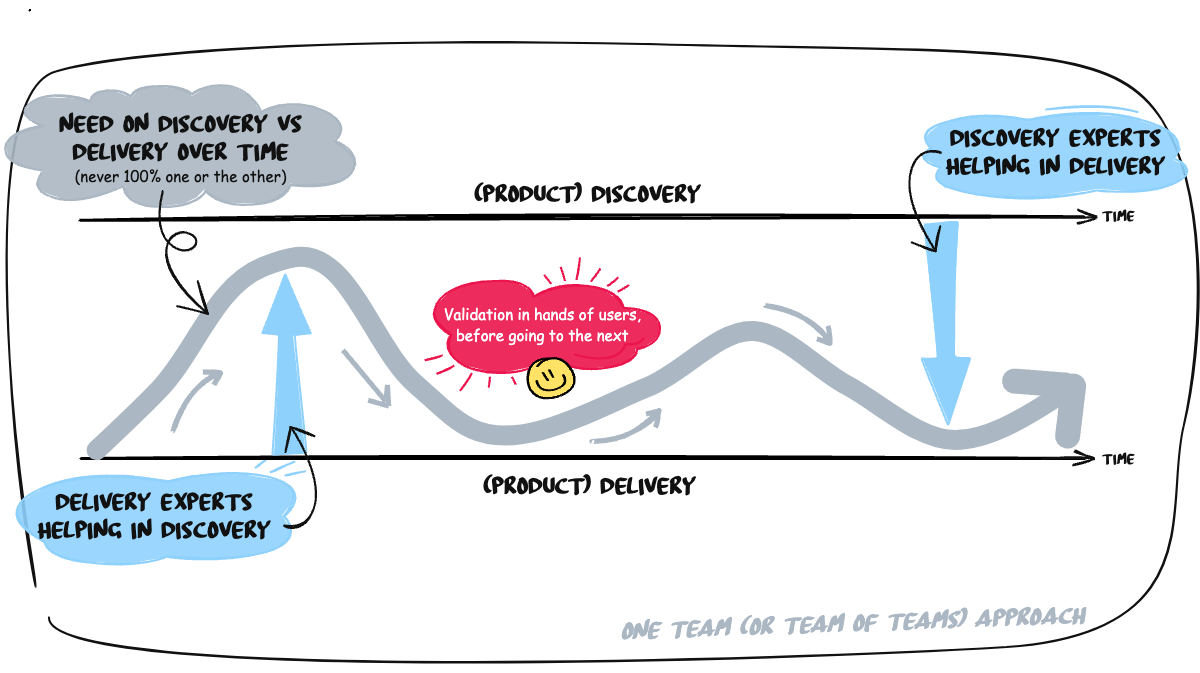
Therefore, bringing teams closer to customers and users means establishing a better understanding of the customer domain, product objectives, long-term vision, and general context within which problems are solved. Teams realize that those requests, problems, and features are related and fit into larger objectives, like puzzle pieces of a bigger project. From the psychology of learning, we know that the ability to associate new knowledge with existing knowledge significantly reduces cognitive load. A developer who understands the customer domain will require less continuous effort to understand individual needs and problems. A developer starts even to suggest requirements. This contribution can be very valuable since customer lacks perspective of technical possibilities that a developer has.
Therefore, the observed consequence of the above dynamic is that teams with higher customer-centricity and broader product focus and understanding suffer less from cognitive overload than teams with a narrow or specialized focus and knowledge. This is directly opposite to popular thinking about cognitive load.
At the same time, there remains an obvious cognitive load required to understand the bigger picture—hence the popular notion that narrow concern reduces cognitive load. Teams need to spend time with different kinds of domain experts and learn from them. Nevertheless, this effort and cognitive load associated with learning are reduced over time with increased understanding. This cognitive load is much less of a problem than a continuous and never-ending struggle with constant fake requirements for changes and bugs.
We observe interesting behavior in teams with a high customer-centricity and whole-product focus. They start to predict what customers want next or should want, which is almost boring. Developers shift their focus away from understanding volatile low level details in requirements towards more stable and less prone to change larger context of the customer problem space.
Collaborative Refinement Sessions
By connecting customers with product engineers (analysis skills, coding skills, testing skills, security skills, etc.) in refinement sessions where needs and problems are discussed, we apply so-called left shifting, reducing the risk of making the wrong decisions, increasing comfort in the decisions, and reducing stress. Of course, this depends on the group’s ability to make decisions! At first, this might require individuals to develop new collaborative skills, yet once acquired, collaborative decision-making reduces the cognitive load of the participating individuals. At the same time, we reduce the risk of building the wrong things.
The practice of collaborative decision-making directly with customers and other domain experts provides high levels of autonomy to the product engineers in terms of determining what to build and how to build it, instead of being constrained by features described by others.
As collaborative refinement sessions are repeated frequently based on the progress made in solving customer problems or needs (outcomes), they increase the active recall repetition mentioned in relation to Ebbinghaus’s forgetting curve, increasing the expertise needed for the task at hand. As such, this decreases cognitive load, establishing experts in what is important at that moment along the way.
By enabling a group of people to explore needs and problems, they are able to deal with more complex reasoning and decision-making than a single person. At the same time, a group will remember more than a person does, increasing their permanent available knowledge and reducing cognitive load again. Since everyone is present, if you don't remember something, there is likely someone else who does.
However, this highly depends on the effectiveness of how a group of individuals works together, hence the “people and interactions over processes and tools” in the Agile manifesto.
Ebbinghaus’s forgetting curve has been mentioned in this chapter in the sense of repetition, but the mnemonic representation guide given is also useful. Agreeing on (or exploring) certain modeling practices to use during these refinement sessions could be helpful—for example, providing a more mnemonic representation of what’s being discussed and agreed upon can decrease cognitive load for the task at hand.
When a group of people becomes familiar with certain refinement techniques like C4 modeling, UML diagramming, customer journey mapping, impact mapping, event storming, etc., the more easily they can focus and use their cognitive load to explore context instead of the method. That’s what Kahneman in Thinking, Fast and Slow refers to as System 1 and 2 thinking. System 1 is fast and doesn’t require much energy; it’s a kind of habit and happens normally. Contrastingly, System 2 is analytical and requires more energy. The first time people are exposed to refinement techniques, the technique itself will be almost entirely in System 2 and require a lot of energy to follow and pay attention to. Then, if one repeatedly uses the same techniques, that’s when the technique itself becomes System 1, without the need for energy, and all their efforts can be focused on the content at hand.
Consolidating refinement techniques to a couple you can frequently use in the context of your product and solution will increase expertise and collaborative skills, in turn lowering the cognitive load of all involved.
If you want to explore this further, we recommend the following articles:
Well-Thought-Through Routine
In the same line of thought as repetitive refinement techniques, well-thought-through routines will create habits over time and provide room for more energy and effort directed toward content instead of format.
To talk about a routine, it has to have a fixed recurrence, fixed days, fixed timings, and a fixed structure. In that sense, for every recurring meeting or event, there should be a fixed structure so that it becomes a habit over time, reducing cognitive load during that activity. We are talking about refinement sessions, planning sessions, daily scrum sessions, review sessions, etc.
A good routine has a clearly defined goal to achieve and general agreements to keep things effective; is guided by a series of questions to address; and ends with a closing part reviewing its effectiveness.
However, ensure your questions are optimal! Say we asked you, “How is your project going?” We’ll get an answer like "good", "not so bad" and so forth—short answers with not so much meaning to them. Say we rephrase this to, “What could we do to make your project run smoother?” Then, we’ll get totally different answers and related thinking. When you have a detailed routine written down including the right questions to go through each time, more people can facilitate and help in following it, and all are prepared for what’s to come. Even better, because it is always the same, you build habits that don’t need much brain power, reducing the cognitive load for all involved.
Especially routines that require a larger group of participants should be taken into account here. Aside from refinement sessions, we suggest considering multi-team sprint planning sessions and sprint review sessions.
Having effective routines for multi-team events will make it a lot easier for multiple teams to collaborate directly with each other versus having to chase project managers, team leads, and others responsible for cross-team coordination. This reduces wasted time and effort, such as that expended during context switching, over the mid to long term.
For a case study example, see “Coordination and communication improvements through effective routines”
Early Feedback
Collaborative refinement, distributed coordination, and well-designed multi-team routines all help in gaining early feedback from those involved and impacted. Fluid ownership, as described, enables multiple teams to work on real customer needs and problems versus a specific technical or domain piece owned by each team separately. When you own a piece of the puzzle, it is consequently less effective, possibly useless, to gather feedback from real users on its implementation. If you order a car (solution) to get you safely from point A to point B (need) and someone only shows you wheels and rims, would you be able to provide useful feedback in relation to your need? Not really. Those in other roles or functions would need to step in and integrate the wheels and rims with other parts to acquire useful feedback.
The more functions you have in your product development organization, the more handovers it will generate in the name of "each can focus on their own thing". The disadvantage is that teams receive information late from others who prepare (write stories, PRDs, designs…) or capture feedback (issues, usage statistics, value metrics…). Whenever priorities or any other implementation detail change, this is discovered by teams much later, typically just before or during delivery.
Similarly, when manual testing is in place, it delays the feedback cycle between doing something and knowing the results. Consequently, this again leads to context switching.
A delay between an action and its expected results will lead to context switching and higher cognitive load when compared to having (almost) instant feedback on functional and technical quality.
For more details on how to enable earlier feedback, refer to the following chapters:
What About Production Monitoring & Issue Handling?
One aspect that consistently pops up when considering removing all technical ownership of pieces of a customer solution is: “Who’s responsible for production?” Some seem to have the idea that if everybody is responsible, nobody is (See: Myth: The Tragedy of the Commons). We will explore here how product development groups with shared (or no) ownership address that.
Before exploring an organizational design that has fluid or no code ownership, let’s explore one where there is per team technical ownership. In this setup, it is very clear who’s responsible (and thus to blame) when things go wrong in production, namely those with ownership of that piece of the solution.
Yet, is that the most customer-focused approach? Let’s examine things from a customer perspective. As a customer, it is cumbersome to know which piece of the puzzle I’m using is causing an issue, so I can’t contact the right person (or team) directly. Also, the teams themselves have a limited view on what the customers experience as they own just a piece of the solution—consequently, nobody in the team is the right person to take the customer call. Thus, we need several levels of external groups, generally referred to as customer support and 2nd level support to handle incoming issues. They’ll use existing, and in many cases outdated, documentation to make their best guess of which piece of the solution is the cause of the issue reported. Then, they’ll contact the technical owners to address the issue. In our experience, this first guess is not always the right place to be, meaning subsequent guesses must be made, with each guess requiring team members to spend time investigating things on their end. This is until, finally, a cause is found, and a solution can be provided to the customer. To help guide a customer with an issue to the right people, organizations might implement (annoying) “press 1 if… , press 2 if… , press 3 if…” sequences and establish customer support process flows to follow. Of course, this is with good intent—to direct the issue to the right people as quickly as possible. From the customer perspective, there is a lengthy process required to access a decent answer or solution. In large corporations, we observe as internal users become, over time, more knowledgeable—they are equipped with superficial technical knowledge about which component, within its respective team, is most likely causing the issue. This is the extreme opposite of being user-friendly or customer-centric.
To avoid some of these issues, it is a good practice to monitor live production systems and catch issues proactively—before a customer even notices them. In the design with clear technical ownership, each separate piece has monitoring capabilities though one may have more than another or access them sooner, possibly contributing to the true meaning of observability (*). Yet, each technical owner is monitoring a piece of the entire customer solution, and things will surely fall between the gaps. To cover those gaps, another organizational unit is born—one that will monitor the overall solution across all pieces of the puzzle. In some cases, it’s this new unit that will execute all monitoring, including the details of the pieces owned by others. But how does one keep this all in sync? How does one ensure that changes in a piece don't break the monitoring? If the new unit (proactively) sees an occurring issue, how fast can they direct it to the right team or teams to fix it? Will we still be able to fix things before the customers notice? How will the right team prioritize this work compared to already planned and ongoing work? Will they switch contexts?
In our experience, in such a system, many people feel frustrated—the customer because things always take a long time; the customer support unit, as they are continuously redirected to yet another team; the production monitoring unit, as with every new release of a puzzle piece, they must fix their systems; and the teams themselves, as they are frequently bothered with issues that aren’t within their scope of ownership or responsibilities.
But in the end, it is always clear who to blame, isn’t it?
In a system with fluid or no ownership, there is no way to figure out who to blame, or it would take a long time to do so. But how does one deal with issues and live monitoring, even 24/7 support? The three-word solution is: “Ask the teams.”
We have seen many different solutions put in place within the organizations we consult. Let us give you a couple of examples.
(*) More on observability:
Rotating Support & Monitoring Team
An organization that moved from an organizational design of ownership to one without ownership (with 14 teams working as a team of teams) established an on-duty support team to take care of all customer issues as well as monitor the live production systems. This wasn’t a dedicated team that would stay in that role forever; it was a rotating role that each team would pick up at some point. Every 2 weeks, the on-duty role moved from one team to another, so in the end, each team was responsible for customer support and live production monitoring.
The thing that truly made it work for them is that each customer issue the team started working on was owned by that team from start to end, and it was not transferred to the newly appointed on-duty team. When a team started working on an issue, it was the same team that retained ownership until it was resolved. However, this doesn’t mean that this person or team was the one to fix it without support from others! If they can, then that’s great; if they can’t, that’s also great, as they can determine which team can and learn from them. This even comes handy when working on new customer value—if they have questions in that domain, they already know which door to knock on.
At the start of their journey, there was considerable cross-team collaboration required to make it work, and over time, this almost disappeared. Teams broadened their understanding of the entire solution, but that’s not why the cross-team collaboration on issues mostly disappeared. The main reason is that there was a lot more attention to the technical qualities of the solution being built, and thus, there were fewer issues to deal with. If you’re the one taking the call from an angry customer, you’ll code your next feature differently—you’ll add more automated testing, appropriate error handling, sensible logging, etc.
In an organizational design with per team technical ownership, it’s not the teams taking the call from the angry customer; instead, they respond to the customer service employees of the company, and as such, they feel less of an urge to change the way new features are coded. Also, there is more focus on ensuring that you, as a team, is not blamed for something. Instead of focussing in discovering faster the real customer issue, teams sometimes even code solutions to protect their part from blame: excessive slow input data checks (to blame another team) or no checks (to avoid throwing errors), reduce exceptions logging (no exceptions means problem will be shifted elsewhere), etc. As you can imagine, discovering this dynamic requires deep technical knowledge due to subtleties of knowing when such code is justified or not.
On the other hand, in shared ownership context, this on-duty team also stood in for 24/7 support, which is handled by a central phone number and mailbox. Some teams passed the 24/7 from one member to another on a daily basis, while others shifted the burden on a weekly basis. Also, some teams engaged the full team, while others recruited only a couple of team members. Each team could have their own agreements.
Additionally, lots of people had to become familiar with live production monitoring. Similar to the above-described pattern with issues, this also leads to a different approach in coding, where there is immediate attention to live monitoring and security. It took some time, but the benefits experienced were (and are) tremendous!
Rotating Team Representatives
Another organization we worked with had fewer issues to deal with compared to the one in the previous example, and they came up with another solution to their needs relating to issues and production monitoring. They established a system of rotating team representatives: each team, every 2 weeks, would appoint a different team representative in the morning, a bit before the daily scrum of the teams started, and every noon and mid-to-late afternoon, the team representatives came together for a separate routine.
During their routine, they first explored new issues recorded by the person answering the phone or by the customers directly. Each issue was very briefly discussed and then distributed to one of the representatives, who took it back to their team to investigate further and provide a solution. This allowed the representatives to distribute the issues to the team with the most relevant knowledge.
Once all issues were distributed, they moved on to the next item in their routine: monitoring. As a mob or collective, they opened up the production monitoring systems on a big screen and investigated possible arising issues or other things that needed to be taken care of. Also, the issues were distributed amongst the representatives present.
Lastly, they selected a new representative to take care of the customer calls and related 24/7 support duty for the next 24 hours. In their case, not everybody was willing to undertake the 24/7 support duty (mainly because of family responsibilities) and, while you might assume otherwise, this was not considered an issue as there were enough people to spread the burden. All accepted that not everybody in their organization (with seven teams of teams) had the same liberty as others to take up this kind of responsibility. When a responsible person was assigned to customer support who could not take calls outside office hours (or weekends), they arranged a buddy that would do so. Everyone took customer calls during office hours, but not everyone took customer calls outside office hours.
With this client, we observed similar benefits arising in the way new features were being developed, including more attention paid to monitoring, quality, error handling, logging, security, etc.
Component Guardians for Business-Critical Components
Another client, with a bit more technical debt, chose to add component guardians to some of their business-critical components (or systems). This concept comes with ownership in production, without ownership in creation.
For a couple of their business-critical components, they configured their source control system to notify 2-3 experts of that component when changes were made by others (either by email, Slack, or Microsoft Teams, depending on the expert that became a guardian at that moment). This was not a PR (pull request) system; it was a simple notification system, and if nothing happened with the notification, the change that was made went into production. When there is no ownership in creation, everyone can make changes that go into production, even those not appointed as guardians.
It was the guardian’s responsibility to review changes made to the component they guard. If they ignored this responsibility and things broke in production, they were still the person that needed to fix things—hence, ownership in production. As you can imagine, when change notifications came to the appointed guardians, they would review the code. If things weren’t done well enough, they paired up with the person that made the change and adjusted, automatically making things more readable and testable over time.
These guardians also monitored their specific piece of the puzzle in production in any way they found suitable. Some had a second screen with their monitoring system always up and running; others agreed on timely investigations; and others agreed on rotating responsibilities between the 2-3 guardians appointed. Anything was acceptable as long as it worked for them.
Over time, we have observed less need for guardians as business-critical components were refactored, became readable by all, and increased in stability, so the guardian configuration became obsolete. A win–win for all: the teams, the guardians, and more importantly, the customers.
In conclusion, there are many ways a group of teams can take up responsibility for customer issues and live production monitoring. What is most important is that the option is chosen or defined by the teams themselves and not forced upon them. This is the only way (we feel) it can provide the right level of ownership to deal with production issues and monitoring in a truly effective manner.
So, what about the problem that if everyone is responsible for something then nobody feels responsible? The teams solve this by explicit and dynamic working agreements. This is fundamentally different from solutions in organizational structure (roles, responsibilities, layers, reporting lines). The key difference is decoupling between what is long term job everyone has (using expertise to fully solve customer problems together with others) vs. task we have today or this sprint (providing specific support or delivering a feature), which is not constrained by the long term job in any way and very dynamic. In such groups, when discussing and making working agreements, individuals and teams typically don't say: "but but that is not my job."